먼저, N+1 문제란 무엇일까?
ORM(Object-Relational Mapping) 기술을 사용하는 경우에 발생할 수 있는 문제로,
연관 관계가 있는 데이터를 조회할 때, N번의 쿼리가 추가적으로 발생하는 것을 말합니다.
ORM 기술에는 익히 들어본 Spring Data JPA, Hibernate 등이 있습니다
표현 방식의 측면에서 N+1 문제와 1+N 문제의 상황으로 나눌 수 있습니다.
(둘은 같은 개념이고 나가는 쿼리 수도 동일합니다)
다음 예시를 통해 살펴봅시다.
N+1 문제 (일대다 관계) : 하나의 부서에는 여러 명의 직원이 존재하고, 모든 부서를 조회하는 상황
- 한 번의 쿼리로 모든 부서를 조회
- 이후, 각 부서별로 N번의 쿼리를 추가로 실행하여 각 부서의 직원 정보를 조회
→ 부서 조회에는 한 번의 쿼리가 필요하지만, 직원을 조회하기 위해 N번의 추가 쿼리가 발생합니다.
→ 일대다(1:N) 관계 중 일(1)인 부서의 측면에서 N+1 문제가 발생한다고 말합니다.
1+N 문제 (다대일 관계) : 여러 개의 주문이 한 명의 고객에 의해 생성되었고, 모든 주문을 조회하는 상황
- 한 번의 쿼리로 모든 주문을 조회
- 이후, 각 주문별로 한 번의 추가 쿼리를 실행하여 해당 주문의 고객 정보를 조회
→ 주문 조회에는 한 번의 쿼리가 필요하지만, 각 주문의 고객 정보를 가져오기 위해 N번의 추가 쿼리가 발생합니다.
→ 다대일(N:1) 관계 중 다(N)인 부서의 측면에서 1+N 문제가 발생한다고 말합니다.
둘을 합쳐 통상적으로 N+1 문제라고 불립니다.
그럼, 이 N+1 문제는 어떻게 해결할 수 있을까요?
N+1 문제는 조회하는 데이터 양에 따라 비례적으로 증가하는 쿼리문과 그에 따른 성능 저하가 문제입니다.
그렇기 때문에, 최대한 한 번의 쿼리문에 필요한 정보를 조회하도록 하는 것이 궁극적인 개선 방법일 것입니다.
사용할 수 있는 해결책은 대략 4가지입니다.
- JPQL의 JoinFetch
- @EntityGraph
- Hibernate의 @BatchSize
- FetchType.EAGER
먼저, JPQL의 JoinFetch와 @EntityGraph의 방법을 알아보기 전에 문제가 될 만한 메서드는 다음과 같습니다.
public interface MemberRepository extends JpaRepository<Member, Long> {
List<Member> findAll(); // N+1 문제가 발생할 수 있는 예시
}모든 Member를 조회하고, 각각의 Member가 작성한 Board들을 함께 조회하는 메서드입니다.
이제 최적화 방법을 알아봅시다.
JPQL의 JoinFetch
Repository 인터페이스의 메서드에 애너테이션을 적용하는 방법입니다.
public interface MemberRepository extends JpaRepository<Member, Long> {
@Query("SELECT m FROM Member m JOIN FETCH m.boards")
List<Member> findAllWithBoards();
}JPQL을 통해 직접 쿼리문을 작성합니다.
'JOIN FETCH'를 사용해서 관련된 게시글들(m.boards)을 함께 로딩하기 때문에,
추가적인 쿼리 호출 없이 회원 + 회원과 관련된 게시글을 함께 가져올 수 있습니다.
JPQL의 JoinFetch은 기본적으로 Inner Join(내부 조인)을 합니다.
@EntityGraph
Repository 인터페이스의 메서드에 애너테이션을 적용하는 방법입니다.
public interface MemberRepository extends JpaRepository<Member, Long> {
@EntityGraph(attributePaths = "boards")
List<Member> findAll();
}attributePaths의 값으로 boards를 지정해서, JPQL의 JoinFetch와 마찬가지로 관련된 게시글들을 함께 로딩합니다.
(attributePaths에 설정한 엔티티는 FetchType.EAGER로 동작하고, 설정하지 않으면 모두 FetchType.LAZY로 동작합니다)
JPQL의 JoinFetch와 비슷한 동작을 하지만, 기본적으로 Outer Join(외부 조인)을 한다는 점이 다릅니다.
여러 엔티티와 조인하기 위해서는 다음과 같이 {}를 통해 작성할 수 있습니다.
public interface MemberRepository extends JpaRepository<Member, Long> {
@EntityGraph(attributePaths = {"boards", "likes", "comments"})
List<Member> findAll();
}
@BatchSize
엔티티의 필드에 애너테이션을 적용하는 방법입니다.
@Getter
@Entity
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class Member {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(nullable = false)
private String name;
@OneToMany(mappedBy = "member")
@BatchSize(size = 10) // 일괄적으로 10개씩 로딩
private List<Board> boards = new ArrayList<>();
@Builder
public Member(String name, List<Board> boards) {
this.name = name;
this.boards = boards;
}
}
위와 같은 설정으로, boards 컬렉션을 10개씩 일괄적으로 로딩할 수 있습니다.
이렇게 되면, N+1문제가 발생하지 않고 필요한 데이터를 한 번의 쿼리로 로드할 수 있습니다.
하지만, @BatchSize 어노테이션만으로는
Member 엔티티의 boards 컬렉션을 모든 쿼리에서 일괄적으로 로딩하지는 않습니다.
한마디로, @BatchSize 어노테이션은 해당 엔티티의 로딩 방식에만 영향을 주고,
findAll() 메서드에는 직접적으로 적용할 수는 없습니다.
따라서, 위의 JPQL의 JoinFetch를 함께 사용해서 일괄적인 로딩을 수행할 수 있습니다.
FetchType.EAGER
Member와 Board가 일대다(1:N) 양방향 관계일 때, 각각의 엔티티에 다음과 같은 설정을 해줄 수 있습니다.
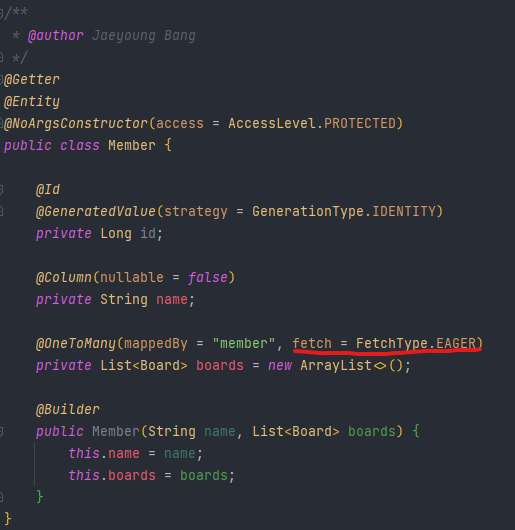

기본적으로 아무런 FetchType을 명시해주지 않으면, 다음과 같습니다.
- @ManyToOne, @OneToOne : FetchType.EAGER
- @OneToMany, @ElementCollection : FetchType.LAZY
(오른쪽의 Board 엔티티에서는 굳이 EAGER 타입을 명시해주지 않아도 됩니다)
EAGER로 설정하게 되면, 관련된 엔티티 데이터를 한 번에 가져옵니다.
따라서, 나가는 쿼리문의 개수는 줄어들 수 있습니다.
하지만, 쿼리가 복잡해지고 DB에서 가져오는 데이터의 양이 증가하기 때문에, 이로 인한 성능 저하가 발생할 수 있습니다.
또, 불필요한 데이터를 로딩할 수 있으며, 복잡하거나 깊은 연관 관계의 경우 문제가 더 복잡해질 수 있습니다.
따라서, 이 방법을 추천드리지 않습니다.
xxxToOne의 모든 fetch 속성은 LAZY로 설정하시는 게 성능 최적화하기에는 더 편합니다.
(LAZY로 설정하면, N+1 문제를 쉽게 확인하고 다른 성능 최적화 방법으로 최적화할 수 있기 때문입니다)
위 4가지 방법들은 모두 특정한 한계점을 가지고 있고, 상황에 맞게 적절하게 골라 사용할 필요가 있습니다.
그 중 Pagination과 관련된 한계가 각각 존재합니다.
1. JPQL의 JoinFetch, @EntityGraph
모든 관련된 데이터가 한 번에 로드되기 때문에 Pagination에 제약이 있을 수 있습니다.
예를 들어, 한 페이지에 10개의 엔티티를 로드하려고 할 때,
의도와는 다르게 두 방법은 한 번에 연관된 데이터를 모두 로드하기 때문에 성능이 저하될 수 있습니다.
2. @BatchSize
@BatchSize는 지정한 크기만큼의 데이터를 일괄적으로 로드합니다.
만약, 지정한 크기가 Pagination에서 지정한 size 보다 더 크다면,
이 또한 과한 로드이므로 성능 저하를 초래할 수 있습니다.
외에도 성능 최적화를 위한 방법은 다양합니다. 궁금하신 부분은 더 찾아보시면 좋을 것 같습니다.
(Hibernate의 @Fetch(FetchMode.SUBSELECT), EntityGraphs와 JPA의 Named Entity Graphs, ...)
가장 추천드리는 수순은
1. 일반적으로 모든 @ManyToOne, @OneToOne에는 fetch 속성을 FetchType.LAZY로 설정하기
2. N+1 문제가 발생한다면, JPQL의 JoinFetch, @EntityGraph, @BatchSize를 사용해보기
3. 그럼에도 N+1 문제가 해결되지 않는다면, FetchType.EAGER를 고려해보기
언제나 피드백 환영합니다.
'Develop > Spring' 카테고리의 다른 글
| 벌크 연산으로 인한 데이터 값 불일치 문제 해결하기 (0) | 2023.08.29 |
|---|---|
| 서버에서 내려주는 에러 메시지를 직접 정의해야만 하는 이유 (0) | 2023.04.22 |
| 트랜잭션 적용 순서 (0) | 2023.01.25 |
| @Value 애너테이션으로 값을 불러올 때, 항상 null 값이 오는 경우 (0) | 2023.01.10 |
| application.properties 파일에 민감한 정보 담기 (0) | 2023.01.10 |


