귤박스 프로젝트에서 초기 단일 게시글 조회 API는 다음과 같은 쿼리 메서드를 사용했다.
public interface PostRepository extends JpaRepository<Post, Long> {
Optional<Post> findByPostId(long id);
}
Spring Data JPA에서 제공하는 단순 쿼리 메서드를 이용했고, 다음과 같이 N+1 문제가 발생하였다.

먼저, N+1 문제가 발생하는 이유는 단일 게시글을 조회 시, 응답되는 데이터 때문이다.
(엄밀히 말하면, 응답되는 데이터라기보다 응답 데이터를 불러오는 방식 때문)
해당 응답 데이터는 다음과 같은 데이터들을 포함한다.
1. 조회하는 게시글의 정보 (Post)
2. 게시글의 작성자 (User)
3. 게시글이 속한 주거 공간 (HouseInfo)
4. 게시글에 달린 댓글들 (PostComment)
이렇게 4개의 SELECT 쿼리문이 호출되고, SELECT USER에 대한 쿼리문이 댓글의 개수(N개)만큼 추가적으로 발생한다. 이는 게시글에 달린 각각의 댓글 작성자에 대한 정보도 함께 응답 데이터로 응답되기 때문이다. 또한, Lazy Loading 전략을 사용했기에 최종적으로 4+N 문제가 발생한 것이다.
N+1 문제를 해결하기 위해, 다음과 같이 Querydsl를 통해 Fetch Join으로 연관된 모든 엔티티를 단번에 조회하도록 개선했다.(Eager Loading처럼 동작)
@Repository
@RequiredArgsConstructor
public class PostCustomRepositoryImpl implements PostCustomRepository {
private final JPAQueryFactory jpaQueryFactory;
@Override
public Optional<Post> findPostById(long postId) {
Post post1 = jpaQueryFactory.selectFrom(post)
.leftJoin(post.user, user).fetchJoin()
.leftJoin(post.houseInfo, houseInfo).fetchJoin()
.leftJoin(post.postComments, postComment).fetchJoin()
.leftJoin(postComment.user, user).fetchJoin()
.where(post.id.eq(postId))
.fetchOne();
return Optional.ofNullable(post1);
}
}
어떻게 보면, 단순무식하게 API의 성능을 고려하지 않고 Fetch Join을 무분별하게 남발한 것 같다. 하지만 결과적으로는 N+1 문제 해결로 호출되는 쿼리문을 1개로 줄였고 DB로 요청되는 부하 또한 줄일 수 있었다.

하지만 2가지 추가적인 문제점이 발생했다.
1. 실질적으로 응답되어야 하는 데이터에 비해 함께 조회되는 불필요한 데이터들이 많다. (댓글이 많을수록 더 많아짐)
2. 해당 쿼리 메서드를 사용하는 API의 응답 시간이 N+1 문제를 해결하기 전보다 오히려 더 증가했다.
N+1 문제를 해결했다고 해서 API 응답 시간이 더 줄거나 성능이 개선되는 것으로 귀결되는 건 아니었다. 단순히 DB 조회에 관련된 성능 이슈를 해결한 것일뿐, 성능 개선을 위해서는 궁극적으로 비효율적인 쿼리를 개선해야 한다는 걸 깨닫게 되었다.
최종적으로 Fetch Join을 사용하되, 연관된 엔티티를 조회하는 작업을 분리하여 성능을 개선할 수 있었다.
먼저 Post, User, HouseInfo를 Fetch Join 해준다.
@Override
public Optional<Post> findPostById(long postId) {
Post findPost = jpaQueryFactory.selectFrom(post)
.leftJoin(post.user, user).fetchJoin()
.leftJoin(post.houseInfo, houseInfo).fetchJoin()
.where(post.id.eq(postId))
.fetchOne();
return Optional.ofNullable(findPost);
}
그 다음 PostComment, User를 Fetch Join 해준다.
@Override
public List<PostComment> findPostCommentsByPost(Post post) {
return jpaQueryFactory
.selectFrom(postComment)
.leftJoin(postComment.user, user).fetchJoin()
.where(postComment.post.id.eq(post.getId()))
.orderBy(postComment.createdAt.asc())
.fetch();
}
위 2개의 쿼리 메서드를 사용한 PostService에서의 단일 게시글 조회 로직은 다음과 같다.
// 게시글 id로 단일 게시글 조회
@Transactional
public PostDto.Response findPostByPostId(long postId) {
Post verifiedPost = findVerifiedPost(postId);
// 조회 수 1 증가
verifiedPost.increaseViews();
List<PostComment> findPostComments = postCommentService.findPostCommentsByPost(verifiedPost);
verifiedPost.setPostComments(findPostComments);
return postMapper.postToResponseDto(verifiedPost);
}
PostComment 조회와 관련된 작업은 PostComment 도메인에서 처리하는 것으로 분리하여 좀 더 유연한 구조로 개선하였다. 처음에 모든 엔티티를 함께 Fetch Join하여 N+1 문제를 해결하긴 했지만, 이는 DB에 또다른 부하를 주었던 것 같다. Response Dto로의 매핑 시에 대량의 데이터가 한꺼번에 조회되고 가공되면서 시간이 소요되었다고 생각한다.
Post, User, HouseInfo / PostComment, User를 각각 따로 fetch join하여 쿼리를 수행한 후에 데이터를 조합하는 방식으로 변경하였고, 필요한 데이터만을 최적화된 방식으로 가져오기 때문에 응답 시간이 감소하게 되었다. 또한, 댓글과 댓글 작성자 정보가 각각 조회되고 세팅되면서 연관된 엔터티들이 불필요하게 중복으로 로딩되는 것을 방지할 수 있었고, 메모리 소비와 응답 시간을 최적화할 수 있었다.

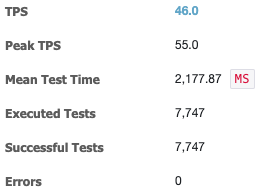
nGrinder를 통한 처음 설계한 API와 최종적으로 개선한 API간의 성능을 테스트한 결과는 다음과 같다.
< 시나리오 구성 >
- 1000개의 댓글 더미 데이터를 DB에 저장 → N+1 문제 발생 시, 총 1000번의 추가 쿼리문 호출됨
- 100 total threads(10 processes * 10 threads / process)로 3분간 해당 API를 요청
| ☑️수정 전 | ✅ 수정 후 |
 |
 |
API의 TPS가 약 4배 정도 증가하였고, MTT 또한 1/4배로 개선된 걸 확인할 수 있다.
물론 API의 성능을 응답 시간이나 TPS만으로 단정지을 수는 없다고 생각한다. 가용성이나 확장성 등 다양한 측면에서 성능 평가가 이루어져야 하고, 성능을 개선하기 전부터 모니터링을 꾸준히 해오면서 여러 가지 부분에 대해 체크해가며 개선점을 확인해야 한다고 생각한다.
nGrinder를 통해 해당 API에 대해 성능 테스트를 진행하면서, 네트워크 환경이나 다소 안정적이고 일관적인 환경에서 테스트를 진행했다고 보기엔 어려운 것도 사실이다. 쿼리를 개선하기 위한 더 나은 방법도 존재할 것이고, 아직 부족한 실력으로 미처 개선하지 못한 부분도 상당히 많을 것이다. (본인은 Setter 메서드를 사용한 것)
해당 개선 과정을 진행하면서, 어떤 부분에서 어떤 쿼리가 호출되는지에 대한 API 동작 과정에 대해 자세히 들여다볼 수 있었고, API의 성능 개선에 대해서도 많은 자료들을 찾아보며 관련 지식을 쌓을 수 있었던 것 같다. 완벽하게 성능 개선을 이뤄냈다기보다는, 과정 속에서 배운 것과 무엇보다 nGrinder를 사용해보았다는 것에 주안점을 두려고 한다. 앞으로도 지식을 습득해나가면서, 개선할 부분들을 찾아 더 다듬어보며 부족한 부분들을 매꾸려 꾸준히 노력할 것이다.
'Develop' 카테고리의 다른 글
| executeBatch()만으로는 부족하다 - MySQL JDBC 성능 최적화 (2) | 2026.04.05 |
|---|---|
| API 성능 테스트를 위한 nGrinder 시작하기 (1) | 2023.12.25 |
| H2 DB - 3가지 모드(Embedded, In-Memory, Server Mode) (0) | 2023.10.05 |
| SQL 쿼리 실행 순서 (3) | 2023.09.27 |
| TCP/IP 4계층 모델 (0) | 2023.07.12 |


